
Event Logs bilden die Grundlage zur Rekonstruktion von Prozessmodellen und damit für das Process Mining. Wie ein solches Event Log beispielhaft aussehen kann und welche Schritte in einem Process Mining Projekt notwendig sind, haben wir im ersten Teil „Process Mining für Dummies“ bereits erläutert. Um den Prozess und damit die Auswahl eines Process Mining Algorithmus, und damit den Ablauf der Rekonstruktion, verstehen und bewerten zu können, folgt in diesem Blog Post die Beschreibung und Unterteilung der Process Mining Algorithmen. Im dritten und letzten Teil dieser Blogserie folgen dann die verschiedenen Typen von Process Mining und warum sie für Compliance Checking Anwendung finden können.
Process Mining Algorithmen
Der wesentliche Bestandteil im Process Mining ist der Algorithmus zur Rekonstruktion von Prozessmodellen. Mit dessen Hilfe wird die Modellerstellung bestimmt. Inzwischen besteht eine Vielzahl an Algorithmen, sodass wir im nachfolgenden auf die folgenden drei Kategorien näher eingehen werden:
- Deterministische Mining Algorithmen
- Heuristische Mining Algorithmen
- Genetische Mining Algorithmen
Deterministisch bedeutet, dass ein Algorithmus immer festgelegte und reproduzierbare Ergebnisse erzielt. Damit ist diese Art von Algorithmus in der Lage immer das gleiche Ergebnis bei gleichem Input zu liefern. Einer der bekanntesten Repräsentanten ist der α-Algorithmus von Wil van der Aalst aus dem Jahre 2002. Es ist einer der ersten Algorithmen, die Gleichzeitigkeit verarbeiten können.
Heuristische Algorithmen verwenden ebenfalls deterministische Algorithmen, enthalten zusätzlich allerdings die Häufigkeiten von Events und Pfaden im Prozessmodell. Leider können auch beim Process Mining sehr komplexe Prozessmodelle entstehen. Über eine Filterfunktion in nahezu allen Process Mining Tools besteht allerdings die Möglichkeit seltene Pfade ein- bzw. auszublenden. Damit kann eine gewisse Komplexität aus dem Modell genommen werden und die Fokussierung auf entsprechende Geschäftsprozesse stattfinden.
Genetische Mining Algorithmen sind ein Spezialfall von heuristischen Algorithmen und verfolgen einen eher evolutionären Ansatz und ahmen Prozesse als natürliche Evolution nach. Die Besonderheit ist, dass sie nicht deterministisch sind. Im Wesentlichen gehen die Algorithmen in vier Schritten vor: Initialisierung, Selektion, Reproduktion und Terminierung. Die grundsätzliche Idee dahinter ist die Generierung von zufälligen Prozessmodellen, die initial nicht viele Gemeinsamkeiten mit dem finalen Modell haben müssen und das anschließende Auffinden einer zufriedenstellenden Lösung. Hierfür werden Individuen iterativ ausgewählt und durch Selektion und Mutation über diverse Generationen reproduziert. Aufgrund der hohen Anzahl von Prozessmodellen in der Population, die Selektion und Reproduktion werden immer besser geeignete Modelle über die Generationen erzeugt.
Die Ergebnisse der Mining Algorithmen können abhängig vom verwendeten Algorithmus somit variieren. Unter Verwendung des nachfolgenden Event Logs aus Tabelle 1, wollen wir unterschiedlich entstandene Prozessmodelle der Mining Algorithmen einmal genauer vorstellen.
| Case ID | Event ID | Timestamp | Activity | Resource |
|---|---|---|---|---|
| 1 | 1000 | 01.01.2013 | (A) Order Goods | Peter |
| 1001 | 10.01.2013 | (B) Receive Goods | Michael | |
| 1002 | 13.01.2013 | (C) Receive Invoice | Frank | |
| 1003 | 20.01.2013 | (D) Pay Invoice | Tanja | |
| 2 | 1004 | 02.01.2013 | (A) Order Goods | Peter |
| 1005 | 03.02.2013 | (B) Receive Goods | Michael | |
| 1006 | 05.02.2013 | (C) Receive Invoice | Frank | |
| 1007 | 06.02.2013 | (D) Pay Invoice | Tanja | |
| 3 | 1008 | 01.01.2013 | (A) Order Goods | Louise |
| 1009 | 04.01.2013 | (C) Receive Invoice | Frank | |
| 1010 | 05.01.2013 | (B) Receive Goods | Michael | |
| 1011 | 10.01.2013 | (D) Pay Invoice | Tanja | |
| 4 | 1016 | 15.01.2013 | (A) Order Goods | Peter |
| 1017 | 20.01.2013 | (C) Receive Invoice | Claire | |
| 1018 | 25.01.2013 | (D) Pay Invoice | Frank | |
| 5 | 1023 | 01.01.2013 | (A) Order Goods | Michael |
| 1024 | 10.01.2013 | (B) Receive Goods | Michael | |
| 1025 | 13.01.2013 | (C) Receive Invoice | Michael | |
| 1026 | 20.01.2013 | (D) Pay Invoice | Michael |
Das Event Log zeigt eine sehr beschränkte Anzahl von Events und Fällen. Um die Funktionsweise der Algorithmen zu demonstrieren reicht die Menge an Einträgen allerdings aus.
Abbildung 1 zeigt einen Prozess nach der Anwendung des α-Algorithmus auf das gezeigte Event Log. Zur besseren Verständlichkeit wurde es in BPMN überführt. Obwohl es sich in dem dargestellten Prozessmodell um einen Einkaufsprozess handelt, lässt sich schnell feststellen, dass es Abweichungen vom idealen Standardprozess gibt. In Fall 3 wurde die Rechnung vor Ankunft der Waren empfangen. Aufgrund der Tatsache, dass sowohl erst die Waren, als auch die Rechnung zuerst empfangen werden kann, geht der Algorithmus davon aus, dass diese Aktivitäten gleichzeitig ablaufen können.
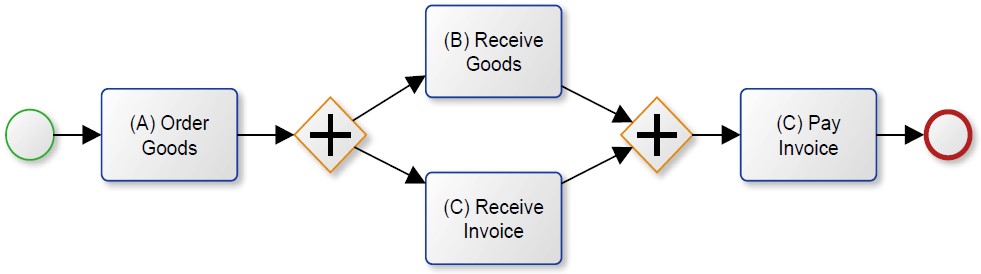
Abbildung 1 Prozessmodell unter Verwendung des α-Algorithmus
Werfen wir einen genaueren Blick auf Abbildung 1, so fällt eine weitere Ungenauigkeit auf. Der 4. Fall wird in dem Prozessmodell gar nicht dargestellt. Es besteht keine Möglichkeit die Sequenz anhand des Prozessmodells aus Abb. 1 abzubilden. Es lässt lediglich zwei ausgeführte Sequenzen zu: ABCD und ACBD, aber nicht ACD. Man beachte an dieser Stelle, dass ein „+“ in BPMN die parallele Ausführung beschreibt. Ein „X“ würde stattdessen auf eine exklusive Ausführung der Aktivitäten hinweisen (exklusives Gateway). Demnach bedeutet das zweite „+“, dass zuvor alle vorangehenden Aktivitäten ausgeführt sein müssen, damit „(C) Pay Invoice“ eintreten kann. Aus diesem Grund ist es laut dem Prozessmodell nicht möglich eine Rechnung ohne erhaltene Ware (wie z.B. Dienstleistungen) zu bezahlen. In dem Fall spricht man von einer schlechten Fitness, da gewisse Sequenzen nicht vom Modell abgebildet werden.
Das Modell in Abbildung 2 kann alle Pfade darstellen. Mit Hilfe des exklusiven Gateways können somit alle drei Sequenzen abgebildet werden (ABCD, ACBD und ACD). Allerdings ist auch dieses Modell nicht ideal, da eine Vielzahl an Sequenzen ausführbar ist, die vom Event Log nicht dargestellt werden. Um genau zu sein, bestehen unendlich Möglichkeiten an denkbaren Sequenzen.
Warum fragen Sie sich?
Das ist eigentlich ganz einfach. Mit dem dargestellten Modell sind Schleifen möglich geworden. Beginnend von B zu C, oder von C zu B, sodass eine unendliche Iteration über die Aktivitäten B und C möglich ist. Damit wäre zum Beispiel die Kombination ABCBCD möglich, die im Event Log allerdings gar nicht enthalten ist.
Wenn ein Prozessmodell zu allgemein ist und mehr Sequenzen zulässt, als in dem Event Log dargestellt werden, so wird es als Under-Fitting bezeichnet und hat eine schlechte Precision. Daher ist eine der größten Herausforderungen des Process Minings die adäquate Lösung zwischen Fitness, Precision, Simplicity und Generalization zu finden. Die Fitness beschreibt wie bereits angedeutet, wie gut ein Modell die Pfade des Event Logs abbildet. Mit der Precision soll Under-Fitting vermieden werden, sodass ein Modell lediglich Pfade zulässt, die auch im Event Log vorhanden sind. Generalization ist entsprechend das Gegenteil von Precision. Das abgebildete Modell soll das beschriebene Verhalten des Event Logs generalisieren. Simplicity spricht in diesem Zusammenhang fast für sich. Ein Modell sollte so einfach wie möglich sein.
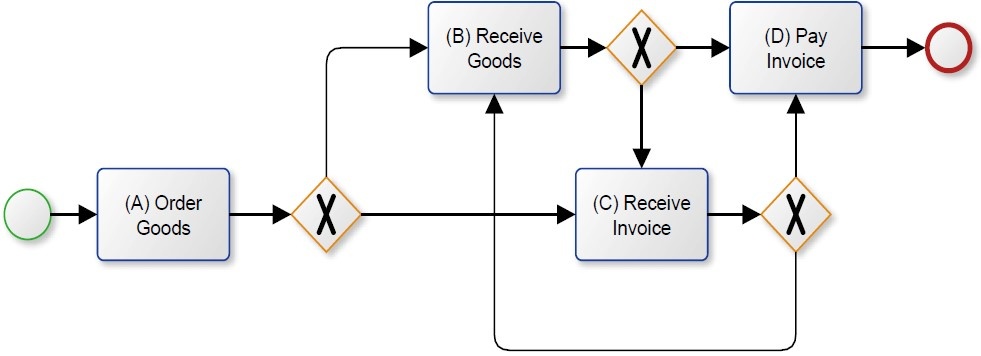
Abbildung 2 Under-fitting Prozessmodell
Inzwischen gibt es eine Vielzahl an Mining Algorithmen, die für verschiedene Vorhaben verwendet werden können. Abbildung 3 zeigt ein Prozessmodell, dass mit Hilfe des Fuzzy Miner Algorithmus nach Günther und Wil van der Aalst 2007 erstellt wurde. Das dargestellte Modell verwendet nicht die BPMN Notation, sondern einen Abhängigkeitsgraphen (engl. Dependency graph). Diese Art der Notation verwendet keine Gateways, sondern stellt die Abhängigkeiten zwischen den einzelnen Aktivitäten dar. So zeigt Abbildung 3, dass in dem vorliegenden Event Log die Aktivität B genau dreimal nach Aktivität A folgt und Aktivität C zweimal.
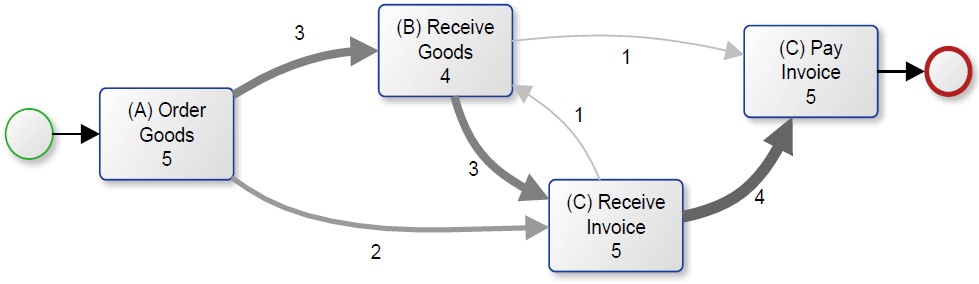
Abbildung 3 Prozessmodell unter Verwendung des Fuzzy Miner Algorithmus
Zusammenfassend ist die Empfehlung eines bestimmten Process Mining Algorithmus daher schwierig bis unmöglich, da abhängig von den verschiedenen Projektanforderungen unterschiedliche Algorithmen in Frage kommen. Demnach sollte stets die Eignung eines Algorithmus im Zuge eines Process Mining Projekts evaluiert werden.
Wenn Sie die Neugier gepackt hat, dann erhalten Sie den kompletten Originalartikel in englischer Sprache unter dem folgenden Link:

Der komplette Beitrag ist erstmalig erschienen: Gehrke, N., Werner, M.: Process Mining, in: WISU – Wirtschaft und Studium, Ausgabe Juli 2013, S. 934 – 943